2| Audio Input/Output Function
As part of enhancing user interaction on the Contoso Outdoors site, we have integrated audio input and output capabilities into the Contoso Chat. This feature allows users to interact with the chatbot using their voice, making the interaction more natural and accessible.
Workflow
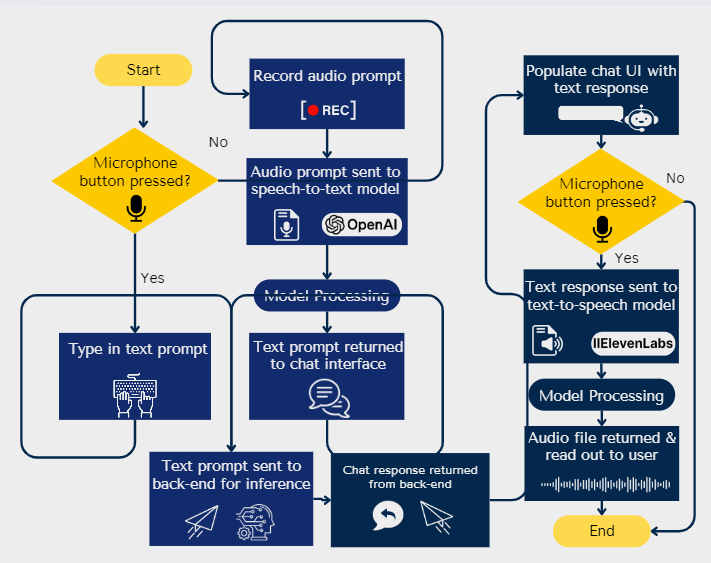
Audio Input
- Start: User initiates interaction by pressing the microphone button.
- Record Audio Prompt: If the microphone button is pressed, the system records the audio prompt.
- Speech-to-Text Processing: The audio prompt is sent to the Whisper-large-v3 model for transcription.
- Text Prompt: The transcribed text is returned to the chat interface and sent to the backend for inference.
Text Input
- Text Prompt Entry: If the microphone button is not pressed, the user types in their text prompt.
- Backend Processing: The text prompt is sent to the backend for inference.
- Chat Response: The response is generated by the backend and returned to the user interface.
Audio Output
- Text Response: The text response is converted to speech using the 11-Labs Turbo V2 model.
- Playback: The audio file is returned to the chat interface and read out to the user.
Models Used
Speech-to-Text Model
- Model: Whisper-large-v3
- Latency: 11583ms
- Features:
- Free use via Hugging Face Inference API
- Multi-language support
Text-to-Speech Model
- Model: 11-Labs Turbo V2
- Latency: 457ms
- Features:
- Free use (up to 10,000 tokens)
- Optimized LLM for real-time applications
Benefits
- Accessibility: Enhances accessibility by allowing users to interact using voice commands.
- Convenience: Provides a more natural and convenient way for users to interact with the chatbot.
- Efficiency: Reduces the time taken for user input and response generation, especially for users who prefer speaking over typing.